-
Story & Technique

Recently I watched two movies that I was quite impressed with. October Sky A boy from a small town becomes inspired by the launch of Sputnik, prompting him to build amateur rockets with his friends and, eventually, work at NASA. I especially liked the dialogue between the father and son, in which the son tries…
-
AI Agents for Coding: Promise vs. Reality

Introduction As a software and infrastructure engineer with decades of experience, I’ve witnessed numerous technological shifts in our industry. Today, I’m exploring what might be another pivotal moment: the rise of AI coding agents. I use various AI tools daily (Perplexity, Repl.it, Gemini app, Claude API, GPT API, Ollama, Tabnine) for different tasks, but recently…
-
Looking beyond JSON Output format from LLMs
While working on my site for Learning and Quiz Generation I noticed that asking LLM’s for JSON outputs was problematic. Too many times the output was not a valid JSON. After multiple such issues, I felt that I should like at other output formats that I can then parse. Once such method that seems to…
-
My Secret Weapon for Selective Exam Writing Practice

That Selective Exam Writing Test… Phew! Here’s Something I Built That’s Really Helping My Kid (And Might Help Yours Too!) If you know what I mean already, head over to the site now to register: https://bussin.trk7.app/ So, your child is gearing up for the Selective Exam? If your household is anything like mine, you know…
-
Upgrading Nginx Ingress Controller from V1.1.1 to V1.12.0
While upgrading the Nginx Ingress Controller, I encountered a few issues with the controller pod startup. Here are the problems and their solutions: 1. Cross-namespace secret is not supported If you have your mTLS CA as a secret in the namespace where the controller is deployed, you’ll face this issue. After the upgrade, the ingress…
-
Going Live on Google Cloud Marketplace
A Technical Lead’s Experience As the technical lead for MOGOPLUS’s recent launch on Google Cloud Marketplace, I want to share our journey and key insights. MOGOPLUS provides insights from unstructured data, primarily serving the lending sector. Our decision to join the Google Cloud Marketplace stemmed from our existing relationship as a GCP customer and our…
-
Gandalf AI – Fun Game
I had a lot of fun fun while playing this game. The objective is for the player to extract password from the system. The first few levels where straightforward and the next few I realised at the end that I could have used almost the same prompt 🙂 For the last one, I had to…
-
Machine Learning for the Lazy Engineer – Vertex AI
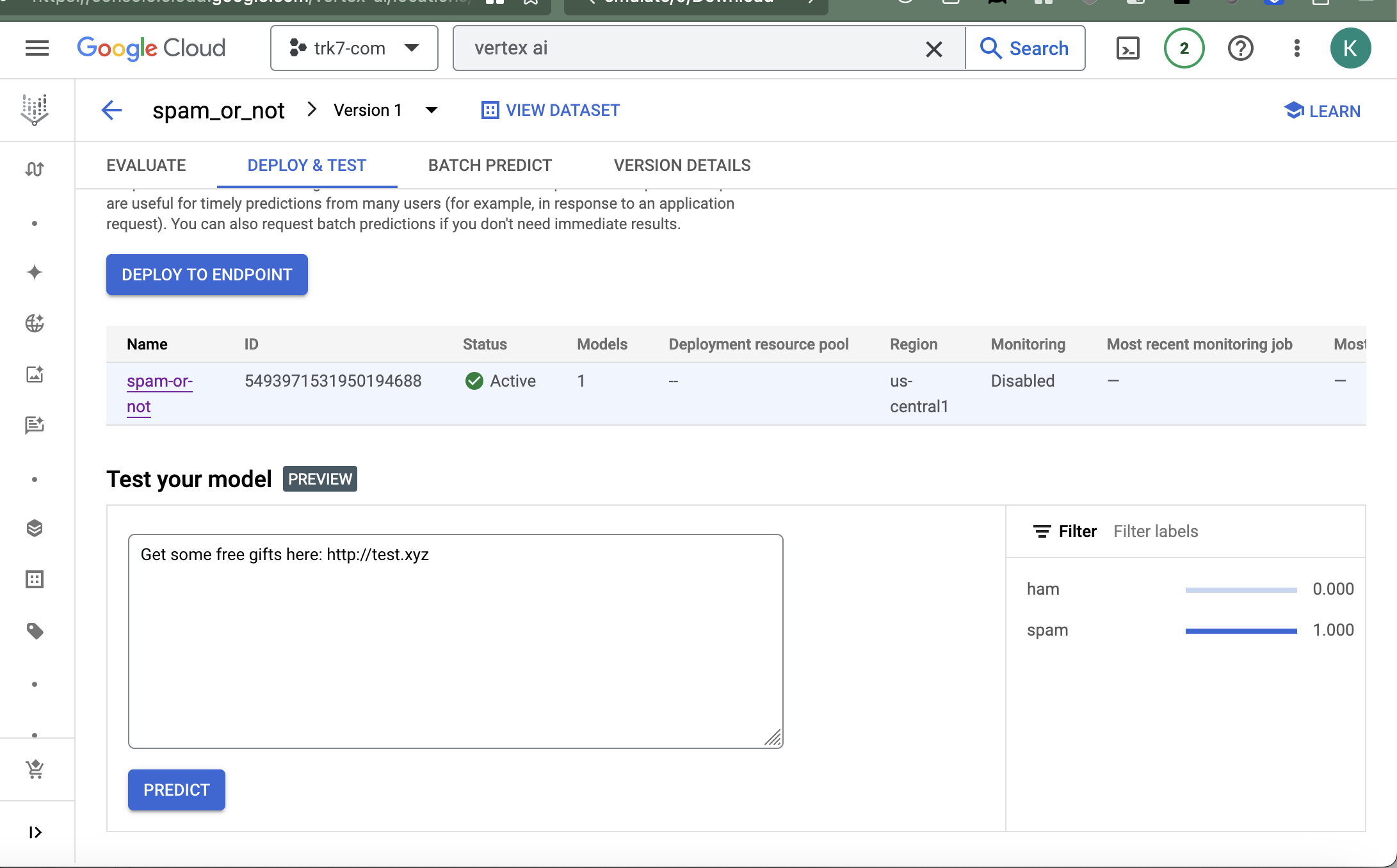
Introduction Using the same dataset and problem that I was trying to solve in Machine Learning for the Lazy Engineer – BigQuery, I am going to show you how to come up with a solution using Vertex AI. I suggest you read through the previous post to get the context. Solution Quoting the heading from…
-
DevSecOps – Acronyms
While dealing with Security Professionals as Devops/DevSecOps person, you will encounter certain terms and acronyms. It helps to understand what they mean and what tools are available for us to satisfy the security requirements. In this blog post, I will list and describe a few terms/acronyms and tools that I have come across relating to…
-
Machine Learning for the Lazy Engineer – BigQuery
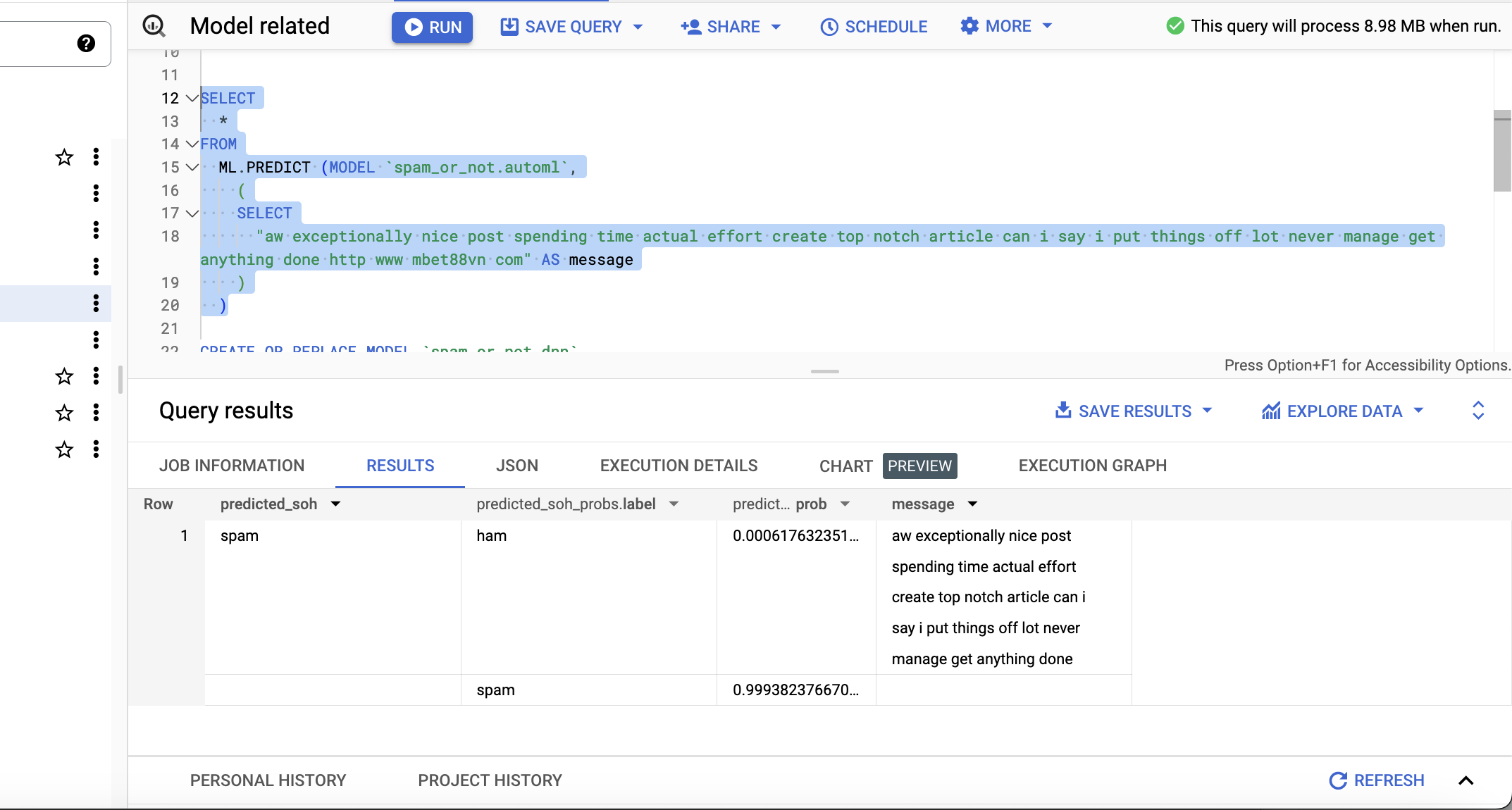
Introduction I first played with machine learning a few years ago when I built an app that applied labels to images of food. I learned a lot during that time, but I found the development setup to be too labor-intensive and my laptop got too hot during training. I got sidetracked with other cloud and…