Introduction
I first played with machine learning a few years ago when I built an app that applied labels to images of food. I learned a lot during that time, but I found the development setup to be too labor-intensive and my laptop got too hot during training. I got sidetracked with other cloud and software projects, so I put the app on hold.
In the meantime, the machine learning landscape has continued to evolve, with ChatGPT and DALL-E bringing machine learning to the masses. However, even now I find the developer experience of training a model and making predictions to be a bit laborious. I’m therefore looking for easier ways to do this, such as using services provided by various vendors.
I’m going to be documenting my experience of developing machine learning solutions as a non-ML developer in a series of blog posts. If you’re interested in following along, it would be helpful to have some knowledge of the following:
- Cloud computing
- General programming skills
- SQL
Developers with an ML background may also learn a few things from my posts.
Let’s get started!
Problem
We have a form on a website that accepts comments. We want to flag Spammy comments.
Solution
BigQuery is a Data Warehouse solution from Google Cloud. BigQuery is serverless and hence we don’t need to maintain any servers. The service automatically scales as required. The process of creating a dataset and table is very simple and straightforward (and hence my like for it). BigQuery service now has ML capabilities, in other words you can create/train/serve one of the many models that are by default available to be used or bring in your own model.
We are going to load some Data, Create a Model and then Train it against the test data. Then we will use the trained model to predict if a comment is spam or not (ham).
Prerequisites
- You have created a GCP Org.
- You have a project with billing enabled.
Steps
- Create the dataset
From the Console, select BigQuery and then create a dataset.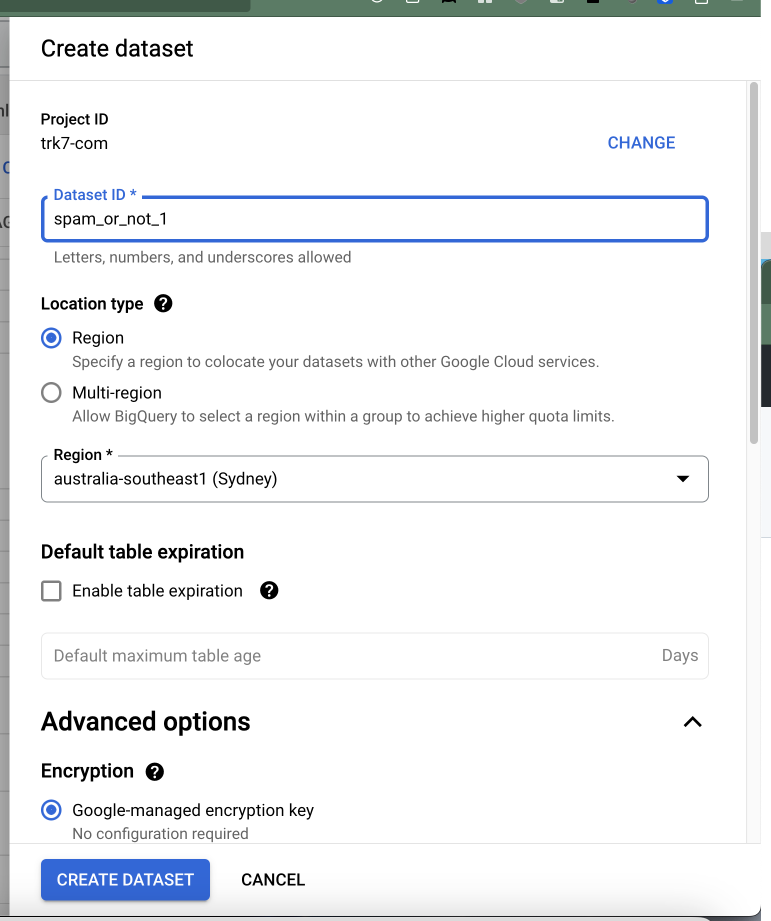
BigQuery Dataset Creation in the GCP Console - Create a Table to hold the Training Data.
You can use the CSV file from here: Spam Or Ham blog comments training dataset to create the table.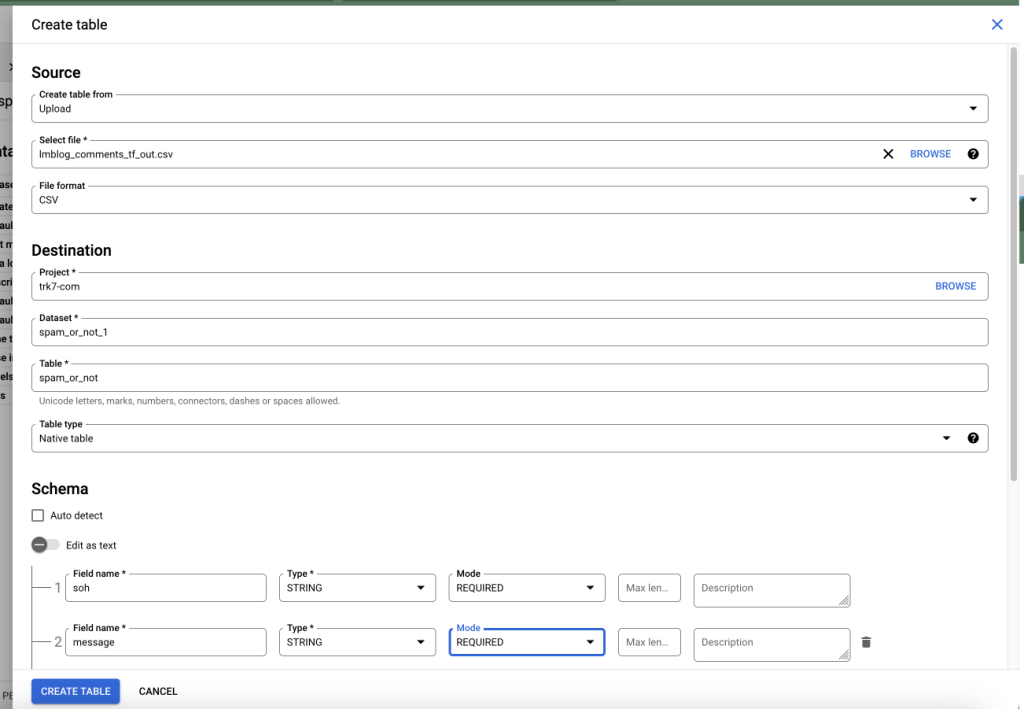
Create a Table using an uploaded CSV File and Schema in BigQuery - Preview the Table
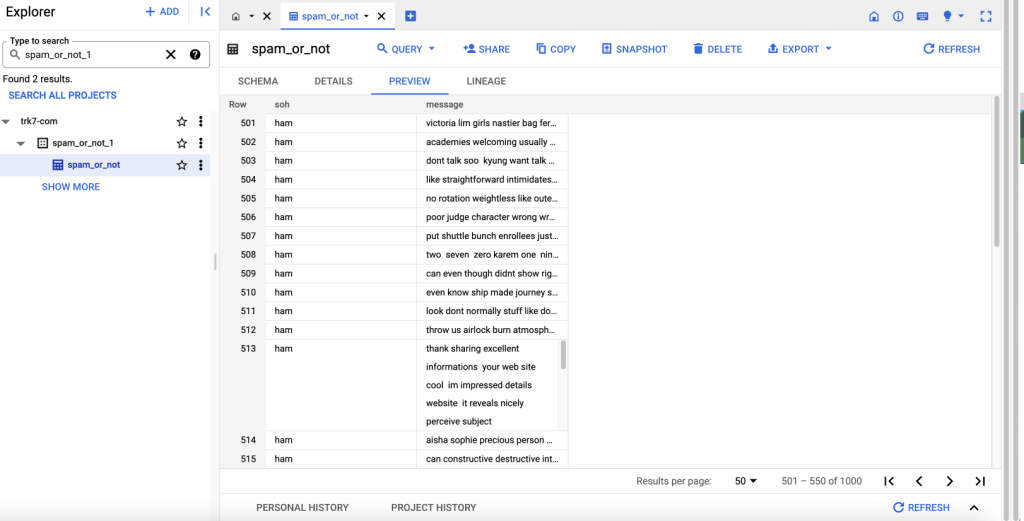
- Create the Model
In the Query Editor, copy and run this query:
I am using the Auto ML Classifier, there are many more models available for use. Auto ML looks at your data and picks the best model and in my short experience this selection works best.
Creating this model took around 3 hours for me, but, I had some additional data (apart from the 1000 rows in the CSV that I linked to at the beginning), and, so your times may be less.
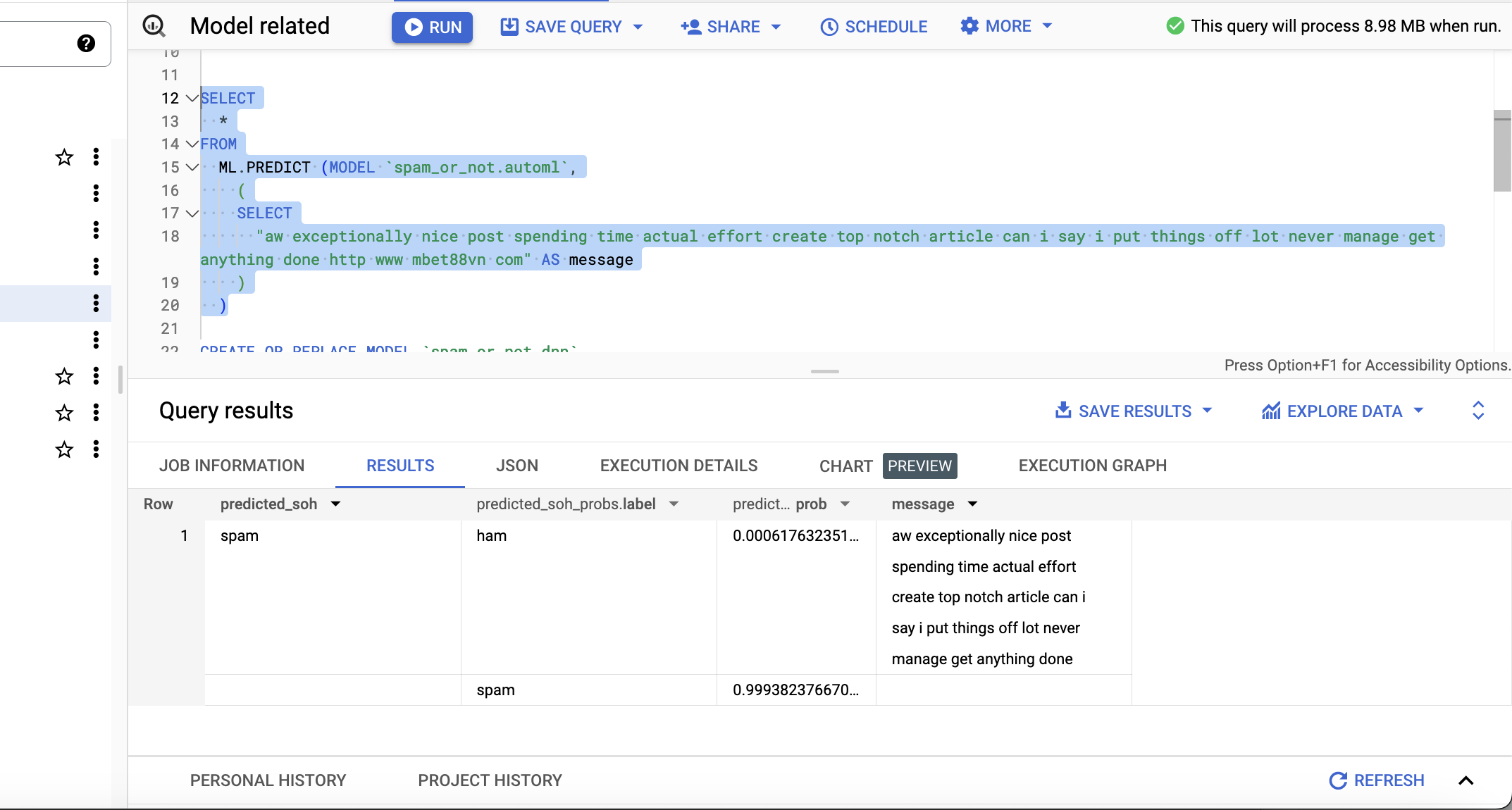
CREATE OR REPLACE MODEL `spam_or_not.automl` OPTIONS(MODEL_TYPE='AUTOML_CLASSIFIER', INPUT_LABEL_COLS = ['soh']) AS SELECT soh,message FROM `spam_or_not_1.spam_or_not` - Prediction
Once the model is created, we can now try to predict if a message is spam or not spam (ham). Run a query similar to below (where aw exceptionally… is a message that we would like to classify, use your own examples).
I see the following in the result (classified as spam with a high probability):
SELECT * FROM ML.PREDICT (MODEL `spam_or_not.automl`, ( SELECT "aw exceptionally nice post spending time actual effort create top notch article can i say i put things off lot never manage get anything done http www mbet88vn com" AS message ) )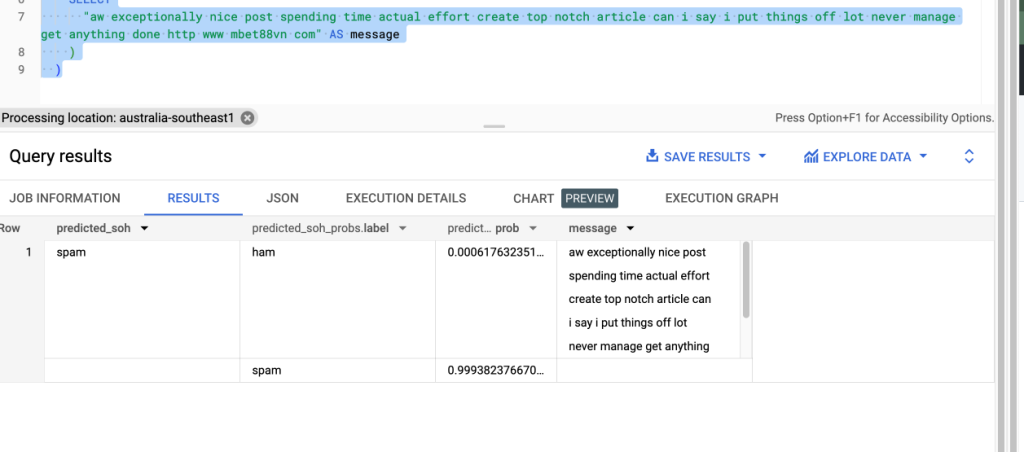
Prediction/Classification result for a single message
Conclusion
Thus I was able to use BigQuery for ML. You can front an API in front of BigQuery, the API could accept a message as parameter to classify and the result will include the classification or you can run this classification in batches. The latter is more ideal, as the predict SQL queries can take a few seconds to return and may not be ideal for an API.
Overall, I was very happy with my experience with BigQuery for ML. I would encourage you to consider this option if it makes sense for your project or if you are just exploring ML.
Links
Tuning BigQuery Classification Model
SMS Spam Collection Dataset
AutoML